Edge computing vs cloud is a defining choice for how modern systems balance performance, cost, and business agility as workloads become more distributed across devices, gateways, and regional data centers, including locations with intermittent connectivity and varying regulatory constraints, which makes technology strategy both practical and strategic. This introductory comparison helps technology leaders understand why latency reduction matters for real-time analytics, industrial automation, and consumer experiences, and it clarifies how pushing compute closer to the edge can shrink round trips, reduce jitter, and preserve bandwidth for critical streams while enabling smarter edge decisions. By weighing edge computing benefits against the cloud architecture’s scalability, global reach, and managed services, teams can design architectures that minimize data movement, support data sovereignty, maintain a defensible security posture, and align governance with the regulatory realities of diverse markets. A pragmatic hybrid cloud edge pattern often delivers the best of both worlds, combining edge inference for immediacy with cloud-scale analytics, governance, and AI model management in centralized repositories, while providing cohesive policy, monitoring, and incident response across distributed components. In this explainer, we outline practical decision criteria and patterns to help you decide where to locate compute, how to partition data, and how to balance speed, control, cost, and compliance, while outlining execution steps, risk considerations, and measurement metrics for ongoing optimization.
Beyond the explicit debate, the core choice can be framed as decentralised versus centralised processing, with on-device and gateway-level compute taking on real-time duties. This perspective invites terms like fog computing, edge intelligence, and distributed analytics, which signal similar ideas from different angles. It also highlights how local data processing can reduce transport load, improve privacy, and enable responsive applications, while remote data stores and centralized services provide scale, governance, and long-term insights. Seen through an LSI lens, topics such as data locality, secure data exchange, API-driven integration, and scalable orchestration connect to the broader discussion of where compute should run. Together, these terms map to a continuum of architectures—ranging from fully edge-native designs to hybrid patterns—that organizations can tailor to their workloads and regulatory requirements.
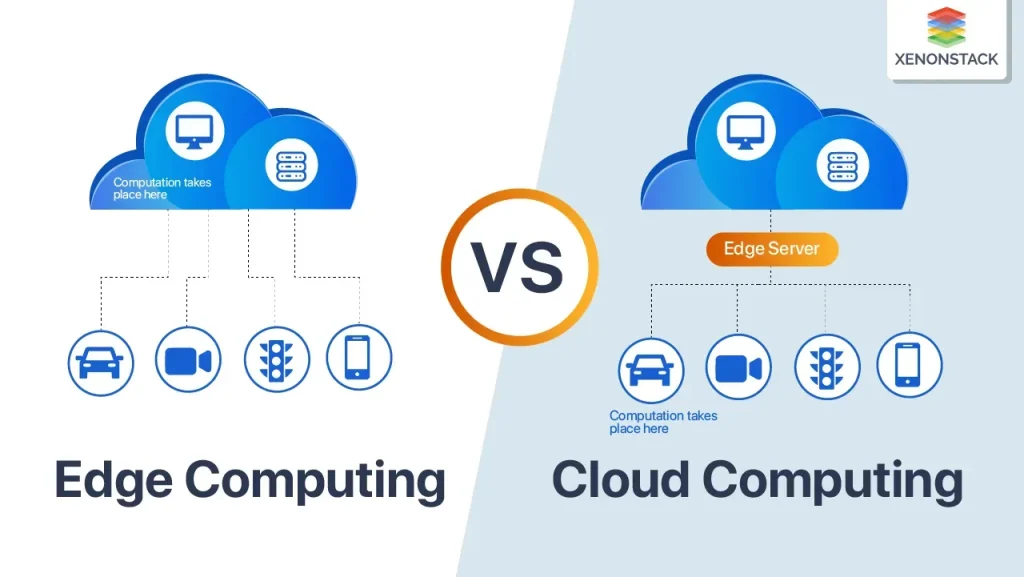
Edge computing vs cloud: A Spectrum of Compute Proximity
Edge computing vs cloud is not a binary choice; it’s a spectrum where the location of compute, data flow patterns, and latency expectations determine the right architecture for a given workload. Pushing processing closer to data sources can dramatically reduce response times and preserve bandwidth, while centralized cloud resources provide scale, managed services, and a mature ecosystem of tooling. Understanding where a workload sits on this spectrum helps teams balance performance, cost, governance, and risk while aligning with regulatory requirements.
For real-time interactions, edge deployments enable local decision-making and faster feedback loops, which is often described as the edge computing benefits. Conversely, cloud architectures excel at large-scale analytics, software updates, and cross-site coordination. A hybrid cloud edge pattern is frequently the optimal middle ground, allowing critical tasks to run near the data source while routing non-time-sensitive processing to the cloud for insights, training, and long-term storage. This approach supports latency reduction without sacrificing scalability, security, or governance.
Latency Reduction as a Core Driver for Edge-first Architectures
Latency reduction is a primary reason to push compute to the edge. For real-time processing in IoT, control loops require milliseconds rather than seconds. By processing streams locally at the edge, organizations cut round-trip time, reduce network bandwidth usage, and improve reliability in environments with intermittent connectivity. This is where edge computing benefits show up most concretely as near-instant insight and local enforcement of policies, while preserving cloud-level agility for aggregation and training.
However, pushing to the edge introduces synchronization challenges and model drift. A balanced approach often uses edge inference for time-critical decisions and cloud-backed retraining for model freshness, with careful versioning and rollout strategies to avoid inconsistencies across devices. Latency reduction should be pursued in tandem with robust observability and secure data flows across edge gateways and cloud services to maintain a coherent global model.
Data Sovereignty in a Hybrid Cloud Edge World
Regulatory requirements around where data resides shape architectural choices. Data sovereignty concerns often force on-premises processing or restricted data movement, especially for sensitive sensor data and personally identifiable information. Edge computing helps meet these obligations by keeping sensitive data within local networks or borders, while using the cloud for non-sensitive tasks and aggregated analytics. In practice, hybrid cloud edge configurations let organizations separate data residency from analytics needs, preserving control over data locality.
Implementing data sovereignty requires clear data partitioning, strong access controls, and auditable data flows across both edge and cloud domains. Governance-by-design patterns ensure lineage, tagging, and policy enforcement travel with data from device to cloud, supporting compliance regimes while enabling cross-environment insights and business intelligence. Aligning data governance with cloud architecture capabilities helps you maintain compliance without stifling innovation.
Cloud Architecture Benefits: Scale, Ecosystem, and Global Reach
Cloud architecture delivers scale, global reach, and a broad ecosystem of analytics, AI, and developer tooling. It enables rapid experimentation, elastic resource allocation, and streamlined security models, with managed services that reduce operational overhead. The cloud’s strength lies in centralized governance, global data services, and the ability to push updates, deploy new models, and run large batch processes with predictable SLAs.
Yet cloud-centric designs can incur higher latency for edge-originating data, higher data movement costs, and potential data residency challenges. Teams often address these drawbacks with hybrid patterns that push latency-sensitive tasks toward the edge while keeping centralized processing in the cloud for scale, governance, and long-term analytics, acknowledging the need for consistent security posture across environments. This is where cloud architecture intersects with edge capabilities to deliver resilient, scalable systems.
Hybrid Cloud Edge Patterns: Practical Designs for Real-World Workloads
A practical hybrid cloud edge approach blends edge-first processing with cloud-enhanced analytics. Core inference and filtering can run at the edge to minimize latency and bandwidth use, while summarized results travel to the cloud for model training, deep analytics, and centralized monitoring. This pattern leverages the edge computing benefits to protect responsiveness and resilience while exploiting cloud architecture for insight generation.
Other patterns include cloud-first with edge acceleration, federated learning, and governance-by-design. Federated learning lets devices contribute to model improvements without exposing raw data, with aggregation performed in the cloud. Data routing policies, orchestration across edge and cloud components, and a unified security model are crucial to avoid fragmentation and maintain data sovereignty where required.
Decision Framework: When to Push Compute to the Edge vs Centralize in the Cloud
To decide where to allocate compute, apply a practical framework that weighs real-time requirements, data locality, bandwidth costs, security, and operational simplicity. If response time is critical, start with edge processing and reserve cloud resources for non-urgent workloads, long-running analytics, and model management. For regulatory or sovereignty constraints, favor edge or local data stores with cloud analytics for broader insights, guided by a clear data governance plan.
As workloads scale, a hybrid cloud edge strategy often delivers the best balance of latency reduction, resilience, and cost. Consider an architectural roadmap that defines data flows, access controls, and monitoring across both domains, and establish a phased migration plan that minimizes risk while expanding capabilities in a controlled, observable way. The result is an architecture that can adapt as technology, regulations, and business needs evolve.
Frequently Asked Questions
How should I approach Edge computing vs cloud for real-time IoT workloads?
For real-time IoT workloads, Edge computing vs cloud tradeoffs favor processing time-critical data at the edge to minimize latency reduction, while the cloud handles batch analytics and broader insights. A hybrid cloud edge pattern often provides the best balance of speed and scale.
Why is latency reduction a key factor in Edge computing vs cloud decisions?
Latency reduction is central: edge computing benefits include near-instant decisions and reduced network traffic, while cloud architecture offers scale but can add round-trip delays for edge-originating data. A blended approach preserves both responsiveness and scalability.
How does data sovereignty influence decisions between Edge computing benefits and cloud architecture?
Data sovereignty considerations may require keeping sensitive data on premises or within specific jurisdictions. Edge computing benefits help satisfy locality requirements, while cloud architecture can support compliant analytics and centralized governance when data moves across regions.
What is hybrid cloud edge, and how does it fit into Edge computing vs cloud strategies?
Hybrid cloud edge combines edge processing for time-sensitive tasks with cloud analytics for deeper insights. This pattern leverages latency reduction at the edge while benefiting from the cloud’s scalability and tooling, aligning with data sovereignty needs when required.
What practical framework guides choosing between Edge computing vs cloud?
A practical framework examines real-time requirements, data locality, bandwidth costs, security, governance, and operational complexity. Map workloads to edge, cloud, or a hybrid setup to optimize latency, cost, and compliance in Edge computing vs cloud contexts.
What are common pitfalls when integrating Edge computing benefits with cloud architecture?
Common pitfalls include overengineering the edge, fragmented tooling, insufficient security, unclear data flows, and poor observability. Use a unified management plane and clear data routing to make Edge computing vs cloud deployments reliable.
| Aspect | Description | Key Benefits & Trade-offs |
|---|---|---|
| Edge Computing | Processing and analytics run near the data source—at devices, sensors, or local data centers to enable real-time insights. | Benefits: reduced latency, lower network traffic, improved privacy. Trade-offs: greater management complexity, security considerations, and update challenges. |
| Cloud Architecture | Centralized or federated compute and storage in data centers or hyperscale regions, providing scalability and rich tooling. | Benefits: vast scalability, global reach, mature tooling. Trade-offs: potential higher latency to edge data, bandwidth costs, and data residency concerns. |
| Latency Reduction | Focus on minimizing round-trip time by processing data locally to speed up actions. | Benefits: faster response times; Trade-offs: data consistency, model update challenges. |
| Data Sovereignty & Compliance | Regulatory rules about where data can reside and how it can be processed. | Benefits: easier regulatory alignment when data stays local; Trade-offs: reliance on cloud for non-sensitive analytics. |
| Hybrid Cloud Edge | A practical middle ground that blends edge processing with cloud analytics and storage. | Benefits: combines latency advantages with cloud scalability and governance. Trade-offs: increased operational complexity and data routing considerations. |
| Decision Framework | A structured approach weighing real-time needs, data locality, bandwidth, security, operations, and compliance. | Guides workload placement to edge, cloud, or hybrid to balance latency, cost, and governance. |
| Patterns & Best Practices | Edge-first with cloud analytics; Cloud-first with edge; Federated learning; Governance-by-design. | Benefits: latency reduction, scalability, and privacy; Trade-offs: tooling fragmentation and orchestration complexity. |
| Common Pitfalls | Overengineering, fragmented tooling, insecure edge devices, unclear data flows, and insufficient monitoring. | Mitigations: run pilots, adopt a unified toolset, enforce strong security, define clear data flows, and implement end-to-end observability. |
Summary
Edge computing vs cloud is a strategic choice about where to run compute, how data moves, and how latency, governance, and cost shape architecture. The discussion shows that edge computing benefits—latency reduction, local decision‑making, and resilience—are strongest for time‑sensitive workloads, while cloud architecture offers scale, global reach, and mature tooling for analytics and AI. A hybrid cloud edge pattern often delivers the best balance by processing near the source and leveraging cloud capabilities for training, governance, and long‑term storage. When designing modern stacks, use a clear decision framework to map workloads to edge, cloud, or hybrid deployments, and adopt practical patterns such as edge‑first analytics, cloud‑first processing, federated learning, and strong data governance. With careful planning, organizations can achieve low latency where it matters, protect data with appropriate sovereignty controls, and scale reliably across environments.